(This explainer post is made for a capstone project in HAISN’s 2nd AI Safety Intro cohort. Congrats to BotJP and Pauloda for finishing the project!)
Introduction
Reinforcement Learning with Human Feedback (RLHF) and Reinforcement Learning with AI Feedback (RLAIF) are important techniques in machine learning.
Same with the pupils who are learned from their teachers and ones who learned from other pupils, RLHF involves using human feedback to align AI behavior with human preferences and values, while RLAIF (created by Anthropic through their “Constitutional AI”) relies on AI-generated feedback to achieve similar goals.
These approaches are particularly significant because they contribute to creating models that are not only safer and more reliable but also better aligned with specific objectives. Furthermore, they enhance the performance of AI systems, especially in applications such as conversational agents and recommendation systems, where understanding and meeting user expectations are crucial.
Core concepts to understand
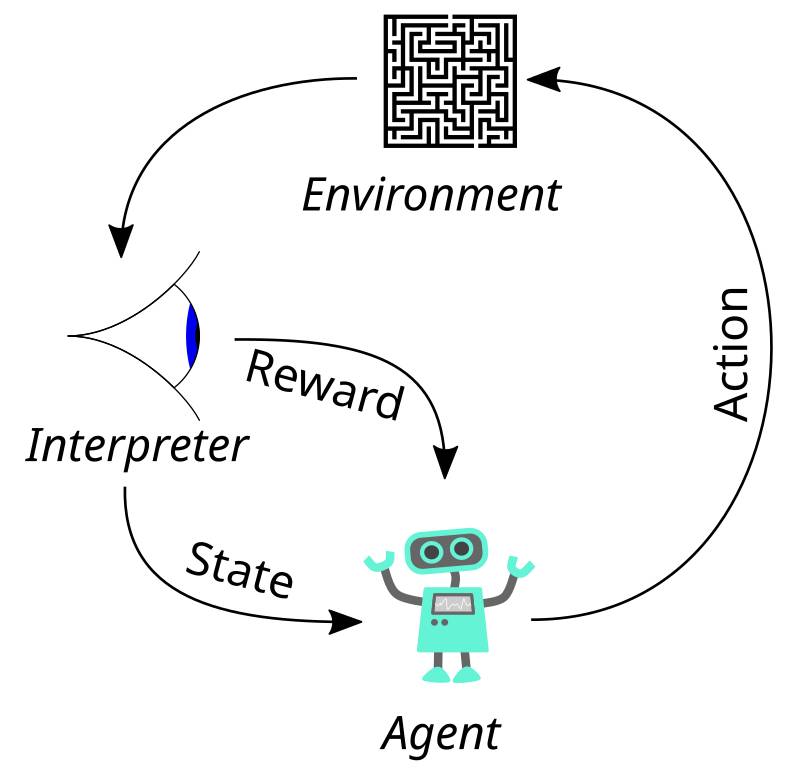
Reinforcement Learning (RL): is an area of artificial intelligence that simulates the way humans learn through multiple trials and errors, ultimately optimizing a policy to achieve the maximum reward.
In this context, the agent serves as the learner that makes decisions based on the information it receives. The policy, which can be thought of as a strategy, drives the behavior of the AI agent by determining how it should act in various situations.
To better understand this process, we can break it down into several components.
First, the state space encompasses all the relevant information about the task that influences the AI’s decision-making.
Next, the action space includes all possible outcomes or decisions that the agent can take. The environment is the setting in which the agent operates, providing the context for its actions. A crucial element of this framework is the rewards function, which acts as a guiding signal for the agent’s actions by creating a measure for the outcomes of its decisions; for example, it can assign scores for completed assignments.
Additionally, constraints are limitations that the agent must adhere to, ensuring that it remains focused on its objectives and preventing it from providing harmful feedback that could be counterproductive while interacting with the environment.
Lastly, preference models are trainable models that predict preferences based on feedback data, further enhancing the agent’s ability to learn and adapt.
Architecture Overview
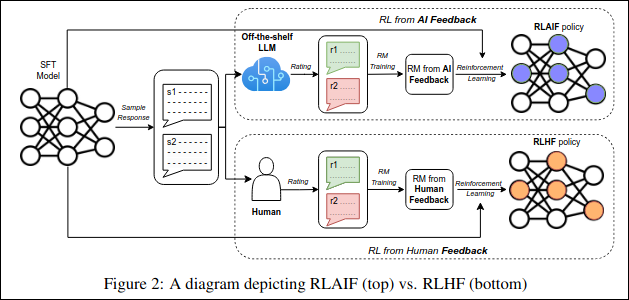
The system architecture of a reinforcement learning framework consists of several key components that work together to enhance the performance of AI models.
We have the pretrained model, which serves as the base model, such as GPT, that has been trained on large datasets from the internet to understand language patterns and generate coherent text, enabling it to predict the next word. This approach is known as “self-supervised learning” since it does not rely on human involvement to generate labels.
Building upon this foundation, the supervised fine-tuning (SFT) model is employed to optimize the available models, enabling them to respond appropriately to various types of prompts. This optimization process is guided by reinforcement learning, which is informed by a reward model that evaluates the quality of the responses.
Next, the training of the reward model (RM) is crucial, as it predicts human or AI preferences by utilizing numerical reward signals. This model automatically provides ratings for each piece of generated text by simulating previous human responses, allowing for a consistent estimation of scores. These scores are then normalized into a reward signal, which informs the agent about the quality of its outputs.
Policy optimization is achieved through the use of Proximal Policy Optimization (PPO), a technique that limits the number of policy updates during each training iteration. This limitation is essential to prevent the model from producing nonsensical outputs in an attempt to deceive the reward system. By carefully managing these components, the system architecture ensures that the AI can learn effectively and generate high-quality responses.
Training Process
The training process in RLHF/RLAIF consists of several essential steps that ensure the model learns effectively while maintaining quality and safety in its outputs.
In RLHF, pairs of outputs are ranked on a scale from 1 - 10 (bad to good), assessing their coherence, relevance, and safety. This ranking helps establish a baseline for what constitutes a good or bad response for preference model.
Alternative to RLHF, RLAIF generates simulated human ranking values to enrich the training data. The subsequent step involves training the reward model, where the score of each output is determined using a pairwise loss function. This function ensures that the distance between similar samples is smaller than that between dissimilar ones, effectively reinforcing the model’s understanding of quality.
Once the reward model is established, the fine-tuning of the model begins. This process utilizes the reward model to guide reinforcement learning through PPO. During this phase, the model’s responses are improved by implementing small, safe updates that do not overwhelm the system, leveraging the previous reward scores. After the reward model assigns scores, PPO makes incremental adjustments to the model, ensuring that its responses become more human-like while avoiding sudden and unstable changes.
An important aspect of this training process is finding a balance between Exploration and Exploitation.
Exploration involves seeking new responses to discover better strategies and outcomes, while exploitation focuses on staying within safe zones where responses have already proven to yield high rewards (The model cannot improve effectively if it solely focuses on discovering new approaches while neglecting existing ones, as this would require significant time and resources.
On the other hand, if the model only adheres to safe methods, it risks limiting its problem-solving capabilities, which can hinder its performance during testing). This balance is essential to prevent the model from stagnating in its learning.
Finally, Kullback-Leibler (KL) divergence is employed to measure how much the model has changed during the fine-tuning process compared to its pre-trained state. By comparing the differences between the two probability distributions, KL divergence helps ensure that the model does not stray too far from its original objectives, maintaining alignment with its intended purpose.
Applications
The applications of RLHF (and potentially RLAIF) are vast and impactful across various domains.
One prominent application is in chatbots, where RLHF significantly enhances conversational agents like GPT, enabling them to engage in more natural and coherent dialogues. In automated systems, RLAIF could facilitate scalable alignment in non-critical environments, ensuring that these systems operate effectively without extensive human oversight.
Personalization is another key area where these techniques shine, as they allow for the alignment of recommendations based on user habits and frequency of interactions. This leads to a more tailored experience for users, enhancing satisfaction and engagement.
In the gaming industry, AI can adapt to player behavior, as seen with the Xenomorph’s AI in “Alien: Isolation”, which learns and counters player strategies, creating a more challenging and immersive experience.
Other uses include robotics, content moderation, and personalized recommendations, showcasing the versatility of these technologies.
By increasing the efficiency and range of responses, these methods of AI feedback optimize both funding and time compared to traditional human feedback processes, which can be slow and expensive. The training of AI through fine-tuning allows for collaboration with humans, enabling large models to be optimized based on previous iterations. This approach saves time by building on existing knowledge rather than starting from scratch, ultimately leading to more effective and responsive AI systems.
Challenges and Limitations
These approaches seem fine and effective, however, RLHF has its inevitable challenges that we have to deal with.
The people themselves are one of the problems. When training a model like this with RLHF, it is hard to get quality responses from humans. With the same response from the agent, two different people can give different feedback.
Moreover, the agent will learn only from the group of people that train it. Humans can make mistakes due to limited knowledge, care and attention, and even worse, there is a risk that the chosen group of evaluators has someone with harmful biases, opinions or even intentions to poison the training data sets.
In RL, the action space is incredibly large, as it contains all of the possible ways to generate an outcome. Letting humans evaluate all of these possible moves is time-consuming and requires a lot of money. Even if we had enough manpower and money to do so, making a model to learn all of the values just from receiving human grades alone seems impossible, not to mention how people’s perspectives can vary from one to another.
So rather than learning from human feedback, how about we let the AI learn from AI feedback?
RLAIF is this exact idea: we use feedback AI with reward functions to train a model in place of humans.
In RLAIF, the feedback is given by another AI model. The cost will be reduced a lot and the scalability is much higher than RLHF because of automation. However, because RLAIF relies solely on the model used for creating feedback, that model must be well-trained or designed. And because of the pre-created principles, the feedback nuance is limited.
In any case, these approaches can’t prevent the model from its common problems like overfitting and can’t ensure their stability when bringing to use. Overfitting occurs when a model is trained too well on a dataset that includes not only the underlying patterns but also noise and irrelevant details. As a result, the model performs exceptionally well on the training data (high accuracy during the training phase) because it “memorizes” the data instead of truly “learning” the patterns.
However, when the model is evaluated on new, unseen data during the test phase, it fails to deliver the expected results. This is because it has not generalized the problem but has instead memorized specific examples.
You can think of it like a student who has memorized all the answers to practice questions but hasn’t truly understood the concepts. When faced with different but related questions on the test, they struggle to solve them because their knowledge is superficial and not based on understanding.
Future Directions
Future advancements will focus on creating algorithms capable of generating precise and well-aligned responses with minimal dependence on human feedback. For instance, instead of requiring constant human review, AI systems could refine their output by learning autonomously from their errors. It’s similar to a self-driving car that improves its navigation skills after each trip without needing continual human supervision.
At the same time, AI systems will emphasize safety by refusing to fulfill harmful requests, even if the responses seem beneficial to users. For example, if a user asks AI to provide instructions for creating something dangerous, the system should deny the request to prevent potential harm to society and not aligned with human values. By doing so, AI ensures its actions align with ethical standards, protecting both individuals and the broader community.
References
Casper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., Rando, J., Freedman, R., Korbak, T., Lindner, D., Freire, P., Wang, T., Marks, S., Segerie, C., Carroll, M., Peng, A., Christoffersen, P., Damani, M., Slocum, S., Anwar, U., . . . Hadfield-Menell, D. (2023, July 27). Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback. arXiv.org. https://arxiv.org/abs/2307.15217
O’Connor, R. (2024, September 9). RLHF vs RLAIF for language model alignment. News, Tutorials, AI Research. https://www.assemblyai.com/blog/rlhf-vs-rlaif-for-language-model-alignment/
O’Connor, R. (2024c, October 16). How Reinforcement Learning from AI Feedback works. News, Tutorials, AI Research. https://www.assemblyai.com/blog/how-reinforcement-learning-from-ai-feedback-works/?utm_source=chatgpt.com
Lee, H., Phatale, S., Mansoor, H., Lu, K. R., Mesnard, T., Ferret, J., Bishop, C., Hall, E., Carbune, V., & Rastogi, A. (n.d.). RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. OpenReview. https://openreview.net/forum?id=AAxIs3D2ZZ
How to Implement Reinforcement Learning from AI Feedback (RLAIF). (n.d.). https://labelbox.com/guides/reinforcement-learning-from-ai-feedback-rlaif/
Reinforcement learning from AI feedback (RLAIF): Complete overview | SuperAnnotate. (n.d.). SuperAnnotate. https://www.superannotate.com/blog/reinforcement-learning-from-ai-feedback-rlaif
Ibm. (2023, November 10). RLHF. What is reinforcement learning from human feedback (RLHF)? https://www.ibm.com/think/topics/rlhf
Ouyang, Long, et al. Training Language Models to Follow Instructions with Human Feedback. arXiv:2203.02155, arXiv, 4 Mar. 2022. arXiv.org, https://doi.org/10.48550/arXiv.2203.02155.